
Excelシート上で使える、複数の関数を組み合わせた特殊な使い方を説明。
今回は TREND、OFFSET、MATCH を組み合わせることで、
データ点数が多いデータの圧縮方法、およびデータ点数の異なるデータのデータ点数を揃える方法を紹介。
【本記事の目標】
TREND、OFFSET、MATCHを使って
データの圧縮やデータ点数の揃える方法を知ろう
今回組み合わせる関数は下記でも説明していますので、ご参考ください。



データの圧縮やデータ点数揃えの必要性
特に製造業におけるデータ整理関係の業務を行う場合に多いと思いますが、
連続した傾向を確認するデータがあったとき、そのデータを取得する期間やデータ取得の間隔によってはデータ点数が非常に膨大になることがあります。
データ点数があまりに膨大だと、他のデータと色々な比較を行っていくとすぐにファイルサイズが大きくなってしまい、パソコンの動きがどんどん悪化する原因となってしまいます。
1点1点のデータが非常にバラついており傾向をつかむのが困難な場合は難しいですが、例えば下記図のように1本の曲線で描けるようなデータになっている場合は、その曲線傾向を判別できるのであればある程度データを間引いても問題がない場合があります。
むしろデータを間引いてファイルを軽くしておくことで、他のデータとの比較を簡単・高速で実施することができ、メリットの方が大きくなります。
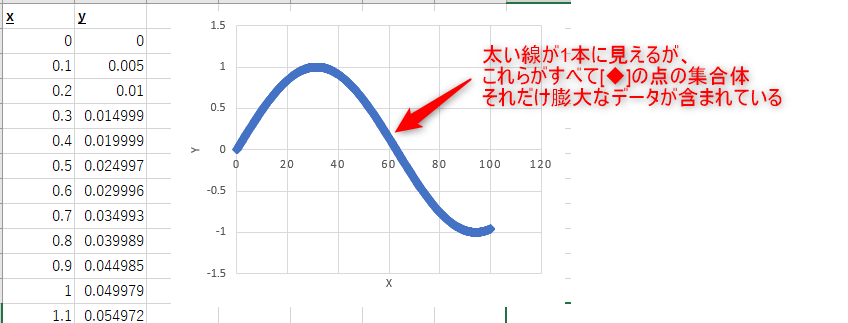
また複数のグラフデータを比較する場合、グラフ化するデータのデータ点数が同じであれば、ひとまとめのグラフを比較的簡単に作ることができます。
データ点数がバラバラの場合、手動だと1種のグラフデータごとにグラフのデータ範囲を設定する必要があり、膨大な手間と時間がかかってしまいます。
そのため、単純に間引くだけでも良いですが、できれば比較するデータに関してはデータ点数を揃えていた方が効率よく比較・解析ができるようになります。
ちなみに単純な間引きを行う方法
できればデータ点数を揃えておいた方が良いですが、単純に間引くだけであれば簡単にできる方法があります。
それはExcelのフィルター機能と下記リンクに記載の特殊な連続データ、特に「一定間隔で繰り返す連続データ」を使います。

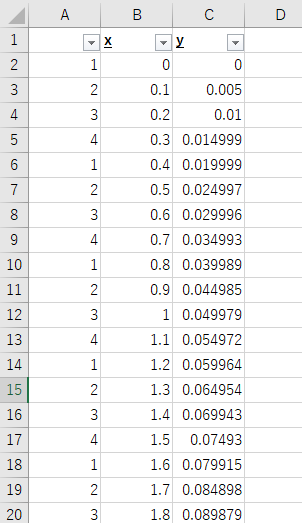
下記図のようにB列・C列に間引きたいデータがある場合を想定します。
まずはA列に「一定間隔で繰り返す連続データ」を記入します。
今回は1~4で繰り返す連続データにしましたが、どの程度間引きたいかによって1~2、1~6等で使い分けます。
連続データの記入が終われば、A~C列にフィルターをセットします。
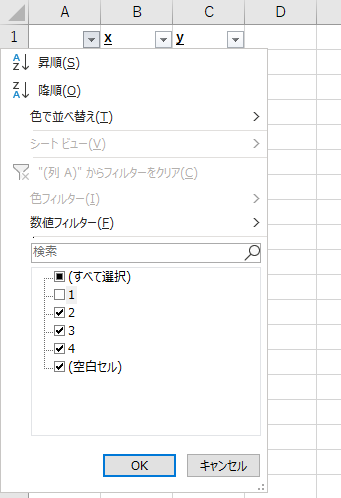
次に、下記のように連続データを記入した列(A列)のフィルターで「1」だけ表示せず、それ以外を表示する設定にします。
フィルターがかかった状態(2~4のみ表示)で行を削除すると、表示されている部分だけが削除されるため、非表示にしていた「1」のデータだけが残り、データ数を1/4まで減らすことができるのです。
連続データの作り方やフィルターの設定の仕方次第ですが、
「1」だけを残すようなフィルター設定をする場合、連続データの繰り返しデータ数の倍率でデータを間引くことができるのです。
(たとえば1~6で繰り返す連続データの場合はデータ数を1/6まで減らすことができます。
このように単純にデータを間引くだけであれば簡単ですが、データ点数を揃えたり、指定のポイントのデータを残しておきたい場合にはこの方法は不向きです。
そのように任意のデータ点数に揃え、かつ指定のポイントのデータを残しながら(もしくはデータの隙間だった場合は埋める)データを圧縮する場合、TREND・OFFSET・MATCHを組み合わせた関数を使うのが有効です。
TREND・OFFSET・MATCHの組み合わせ
TREND関数について
TREND関数は下記記事にも説明している通り、一次関数の近似直線を算出し、指定されたxの値のときに推定されるyの値を返す、という機能を持った関数です。
この記事の中で例として紹介していますが、
このTRENDを使うことで、膨大なデータ点数がある滑らかに繋がったデータについて、
取り回しが容易になるように、指定のデータ点数、指定のxで圧縮することができます。
ただその計算をする場合、「既知のy」「既知のx」を指定する必要があるのですが、
この「既知のy」「既知のx」は、指定するxが存在する部分(であろう部分)の前後いくつかのデータを指定する必要があります。
この「既知のy」「既知のx」を探索する際に、OFFSET、MATCHを組み合わせが必要になってきます。
OFFSETとMATCHの使い方
例として、下記のようにA列・B列に膨大なデータがあるとします。
xの値は0~100の幅でデータ点数は1000あります。
これをJ列にあるようにxの値が同じ0~100の幅で、ただしデータ点数を50に減らしたデータを作りたい(データ点数を1000⇒50に圧縮する)。
この時のK列(yの値)を計算する計算式を作ります。
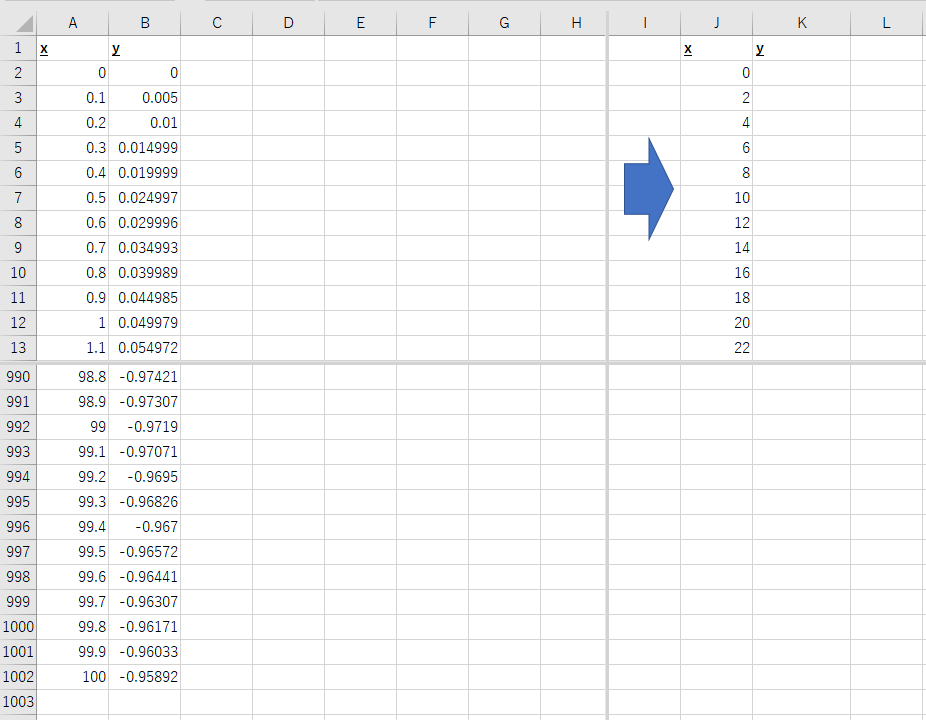
このデータだとJ列にある値と全く同じ値がA列にあるので、VLOOKUP等でデータを取り出すことも可能ですが、全く同じ値が無いと仮定して計算式を作ります。
(通常のデータであれば、全く同じ値がないことの方が多いので)
J列にある値と全く同じ値がA列に無いと仮定すると、
J列のXの値の時にyの値がどうなるかを計算する必要があります。
その時にTREND関数を使うのですが、TREND関数を使うためのデータ(「既知のx」「既知のy」)は、J列のXの値に一番近い値をA列の中から探し出し、そのデータの周辺データを使う必要があります。
この時に使うのがOFFSETとMATCHなのです。
MATCH関数を使った計算
まずはMATCH関数を使ってJ列のXの値に一番近い値をA列の中から探し出します。
計算式は下記のようになります。
=MATCH(J2,A:A,1)
今回A列のデータは昇順に並んでいるため、「照合の種類」には【1】を入力しています。
この計算式をK列に入力すれば、J列のXの値に一番近い値がある場所を表示してくれます。
OFFSET関数を使った計算
データの場所が分かったので、後はその周辺のデータを取ってくれば良いのです。
この時に使うのがOFFSET関数です。
まずXの値をとってきます。
先ほどのMATCH関数で上から何行目にデータがあるかわかっていますので、下記の式でそのポイントのデータを取ってきます。
=OFFSET($A$1,MATCH(J2,A:A,1)-1,0)
ただこれだと1点のデータを取ってきただけですので、この周辺のデータを取ってきます。
計算式で書くと下記のようにOFFSET関数の「高さ」の部分に数値を入力して指定しています。
=OFFSET($A$1,MATCH(J2,A:A,1)-1-5,0,11)
ここでOFFSET関数の「行数」に【-5】を入力し、「高さ」に【11】を入力しているのは、MATCH関数で検索たポイントが「既知のx」で入力するデータの真ん中に来るようにするためです。
この「高さ」は【11】でなくてもよく、例えばI1セルに入力した値を使っても問題ないです。
その場合は計算式は下記のようになります。
=OFFSET($A$1,MATCH(J2,A:A,1)-1-$I$1/2,0,$I$1)
この計算式はXの値ですので、Yの値も同じように取ってきます。
=OFFSET($B$1,MATCH(J2,A:A,1)-1-$I$1/2,0,$I$1)
TREND・OFFSET・MATCHの組み合わせ
上記でOFFSETとMATCHを使って「既知のX」「既知のY」を取ってくることができましたので、あとはTREND関数でその値を入力すれば完成です。
実際にK列に入力する関数は下記です。
=TREND(OFFSET($A$1,MATCH(J2,$A:$A,1)-1-$I$1/2,1,$I$1),
OFFSET($A$1,MATCH(J2,$A:$A,1)-1-$I$1/2,0,$I$1),J2)
この関数を入力すると、下記図の左のように1つの線に見えるほど[◆]のマーカーが集合していたグラフが、右のグラフのように形状は維持しつつある程度隙間があるデータに変わりました。
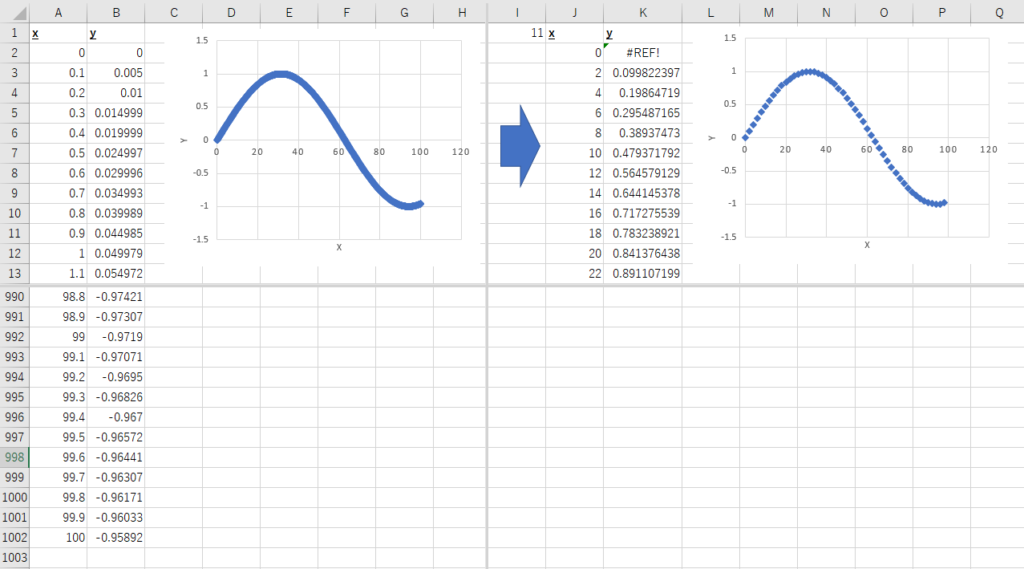
今回は1000個のデータ点数を50個に圧縮しましたが、この方法を使えばどれだけ膨大なデータがあったとしても、任意のXを使った指定されたデータ点数のデータに圧縮が可能です。
膨大なデータのグラフを作ってExcelファイルが重くなってしまっている方は、是非とも試してみてください。
コメント